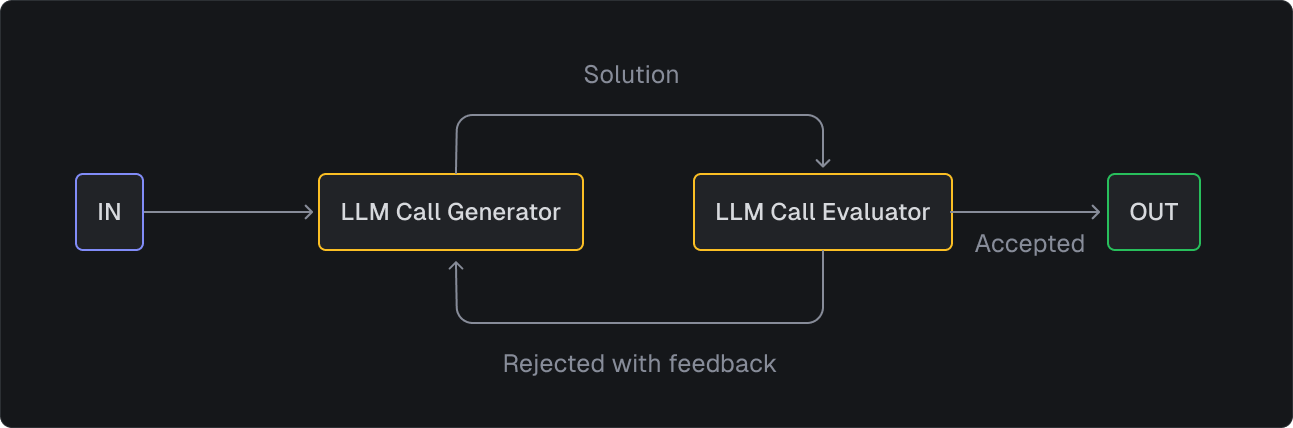
import { task } from "@trigger.dev/sdk";
import { generateText } from "ai";
import { openai } from "@ai-sdk/openai";
interface TranslationPayload {
text: string;
targetLanguage: string;
previousTranslation?: string;
feedback?: string;
rejectionCount?: number;
}
export const translateAndRefine = task({
id: "translate-and-refine",
run: async (payload: TranslationPayload) => {
const rejectionCount = payload.rejectionCount || 0;
// Bail out if we've hit the maximum attempts
if (rejectionCount >= 10) {
return {
finalTranslation: payload.previousTranslation,
iterations: rejectionCount,
status: "MAX_ITERATIONS_REACHED",
};
}
// Generate translation (or refinement if we have previous feedback)
const translationPrompt = payload.feedback
? `Previous translation: "${payload.previousTranslation}"\n\nFeedback received: "${payload.feedback}"\n\nPlease provide an improved translation addressing this feedback.`
: `Translate this text into ${payload.targetLanguage}, preserving style and meaning: "${payload.text}"`;
const translation = await generateText({
model: openai("o1-mini"),
messages: [
{
role: "system",
content: `You are an expert literary translator into ${payload.targetLanguage}.
Focus on accuracy first, then style and natural flow.`,
},
{
role: "user",
content: translationPrompt,
},
],
experimental_telemetry: {
isEnabled: true,
functionId: "translate-and-refine",
},
});
// Evaluate the translation
const evaluation = await generateText({
model: openai("o1-mini"),
messages: [
{
role: "system",
content: `You are an expert literary critic and translator focused on practical, high-quality translations.
Your goal is to ensure translations are accurate and natural, but not necessarily perfect.
This is iteration ${
rejectionCount + 1
} of a maximum 5 iterations.
RESPONSE FORMAT:
- If the translation meets 90%+ quality: Respond with exactly "APPROVED" (nothing else)
- If improvements are needed: Provide only the specific issues that must be fixed
Evaluation criteria:
- Accuracy of meaning (primary importance)
- Natural flow in the target language
- Preservation of key style elements
DO NOT provide detailed analysis, suggestions, or compliments.
DO NOT include the translation in your response.
IMPORTANT RULES:
- First iteration MUST receive feedback for improvement
- Be very strict on accuracy in early iterations
- After 3 iterations, lower quality threshold to 85%`,
},
{
role: "user",
content: `Original: "${payload.text}"
Translation: "${translation.text}"
Target Language: ${payload.targetLanguage}
Iteration: ${rejectionCount + 1}
Previous Feedback: ${
payload.feedback ? `"${payload.feedback}"` : "None"
}
${
rejectionCount === 0
? "This is the first attempt. Find aspects to improve."
: 'Either respond with exactly "APPROVED" or provide only critical issues that must be fixed.'
}`,
},
],
experimental_telemetry: {
isEnabled: true,
functionId: "translate-and-refine",
},
});
// If approved, return the final result
if (evaluation.text.trim() === "APPROVED") {
return {
finalTranslation: translation.text,
iterations: rejectionCount,
status: "APPROVED",
};
}
// If not approved, recursively call the task with feedback
await translateAndRefine
.triggerAndWait({
text: payload.text,
targetLanguage: payload.targetLanguage,
previousTranslation: translation.text,
feedback: evaluation.text,
rejectionCount: rejectionCount + 1,
})
.unwrap();
},
});