

Today we're excited to launch our v4 beta, that includes Run Engine 2.
There are significant performance improvements like warm starts, a totally revamped dashboard, "human in the loop" tokens, and more.
It's very easy to update from v3 – for most projects it will take less than 5 minutes.
Warm starts
When one of your v4 deployed runs finishes the machine will stay running for a while. If there's an available run for that version we will execute it on the same machine.
This drastically reduces start times because we don't need to boot a new machine up. In our tests most warm starts are between 100–300ms.
We have ambitious plans to dramatically improve all start times, including cold starts. To achieve this we'll be switching our cloud execution environment to Cloud Hypervisor MicroVMs. Work will begin on this soon.
Dashboard ❤️ environments
We've redesigned the dashboard so environments are a first class concept. We think you'll find this makes navigation faster and less confusing.
Dashboard improvements include:
- Most pages are now scoped to the environment you're in. This makes pages faster and less confusing.
- We've improved the project and organization switcher.
- For Dev, we now show in the sidebar if your laptop is connected (v4+ only).
- You can pick an icon for your organization.
- We've moved the "Concurrency limits" to the new Queues page. More on that below.
- New "Waitpoint tokens" page. Which neatly brings us on to…
Waitpoints
In v4 we’ve created a new primitive called a “Waitpoint”. They power our existing wait functions and provide additional capabilities, like idempotency keys.
A Waitpoint is something that can block runs from continuing until conditions are met.
A single waitpoint can block multiple runs, and a single run can be blocked by multiple waitpoints.
Waitpoint tokens (human in the loop)
Waitpoint tokens can pause a run until you complete the token (or it times out). They are a powerful primitive in many situations but the most common is for "human in the loop" – do some work then allow a human to reject, suggest changes, or approve.
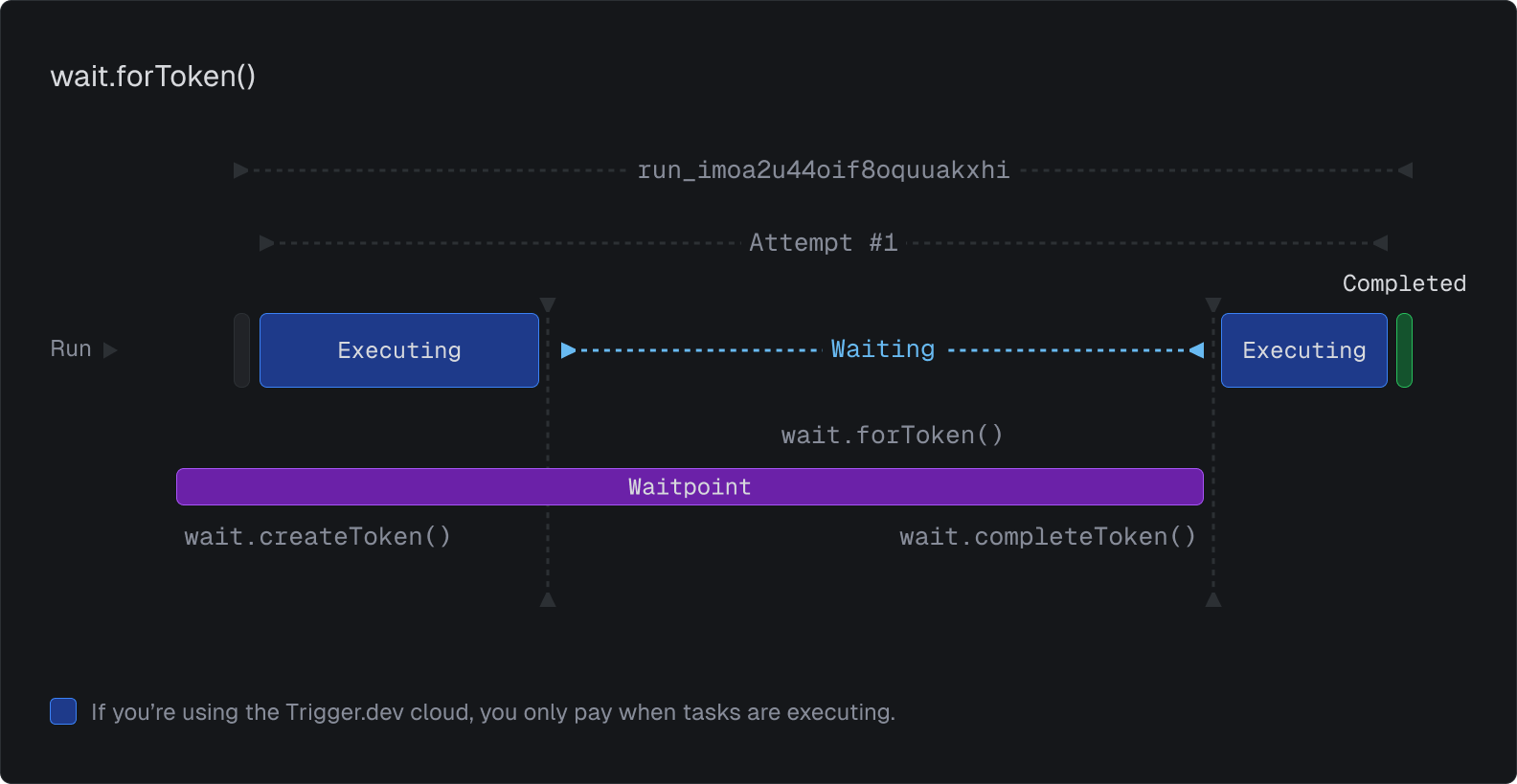
You can build powerful AI agents using these tokens which wait for human approval, like in this example:
// Create a token that times out after 1 day if not completed// Timeouts are optional, the default is noneconst approvalToken = await wait.createToken({ timeout: "1d" });// Trigger a run and pass the token in, you'd do this from your backendawait skynet.trigger({ approvalToken });// A very innocent task that uses the tokenexport const skynet = task({ id: "skynet", run: async (payload) => { await doSomethingVeryInnocent(payload.targetCities); // Wait for the token to be completed const result = await wait.forToken<ApocalypticPayload>( payload.approvalToken ); if (!result.ok) { // This happens when the token has timed out throw new Error("Skynet has been stopped because humans were too slow"); } if (result.output.approved) { await startSkynet({ finalMessage: result.output.closingRemarks }); } else { throw new Error("Skynet wasn't approved. We're safe… for now."); } },});// You can complete the token with data, this would be done from your backendawait wait.completeToken<ApocalypticPayload>(approvalToken, { approved: false, reason: "Nice try but I've seen all the Terminator movies, even the bad ones.",});
This video shows how you can manually complete waitpoints as well as cause them to timeout. Both features are useful for testing.
Idempotency for trigger and waits
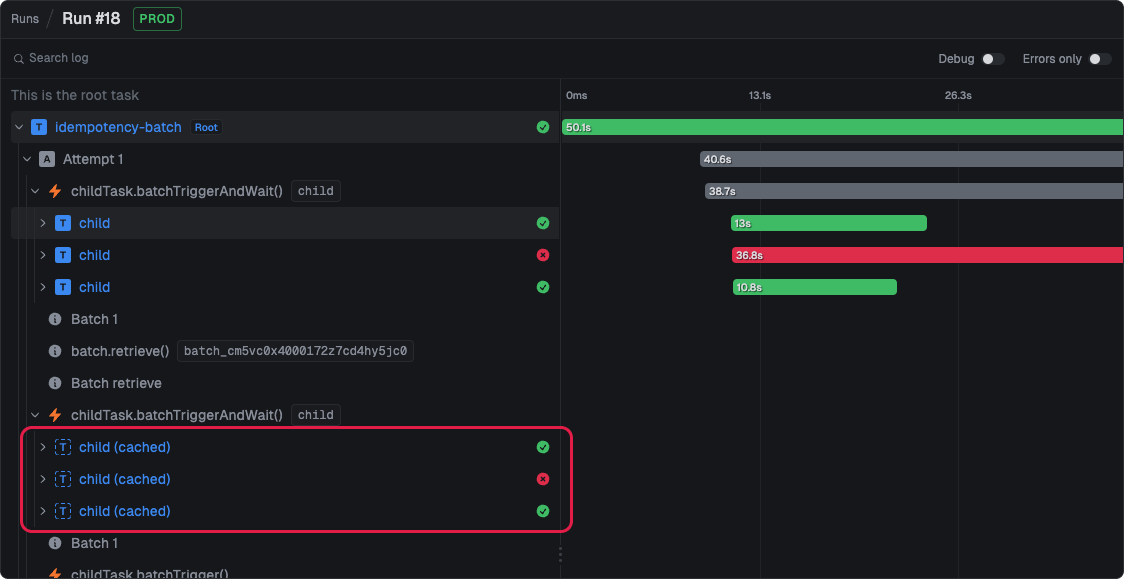
We have added support for idempotency keys when using triggerAndWait(), batchTriggerAndWait() and variants. This allows you to easily cache the result of a run, to avoid doing the same work twice.
// This will run at most once every 5 mins, for this user.id// If you trigger again with the same key, it will instantly return the cached resultconst child = await childTask.triggerAndWait( { foo: "bar" }, { idempotencyKey: user.id, idempotencyKeyTTL: "5m" });// With batch functions you can pass keysconst batch1 = await childTask.batchTriggerAndWait([ { payload: { foo: "bar" }, // Set idempotency for this run options: { idempotencyKey: user1.id, idempotencyKeyTTL: "10m" }, }, { // No idempotency is specified on this run payload: { foo: "bar" }, },]);
We make it clear in the run logs if it's using a cached run result.
Time-based waits with idempotency and dashboard skipping
You can now add idempotencyKey and idempotencyKeyTTL to wait.for() and wait.until(). If you have a run that might fail and you don't want to wait on the second attempt you can use the run id from ctx as the idempotency key.
// This will only wait once with this user.id (in the next hour).// That includes across all runs and tasks.await wait.for({ seconds: 30, idempotencyKey: user.id, idempotencyKeyTTL: "1h",});
You can also manually skip time-based waits in the dashboard, this is very useful when testing:
More waitpoints coming soon
We're going to add more waitpoint functions soon, like wait.forHttpCallback(). This allows you to start some work on another API (or one of your own services) and continue the run when a callback URL we give you is hit with the result.
In this example we start a Replicate prediction and continue the run when the prediction is complete.
Run priority
In v4, you can set a priority when you trigger a run. This allows you to prioritize some of your runs over others, so they are started sooner. This is very useful when:
- You have critical work that needs to start more quickly (and you have long queues).
- You want runs for your premium users to take priority over free users.
The value for priority is a time offset in seconds that determines the order of dequeuing.
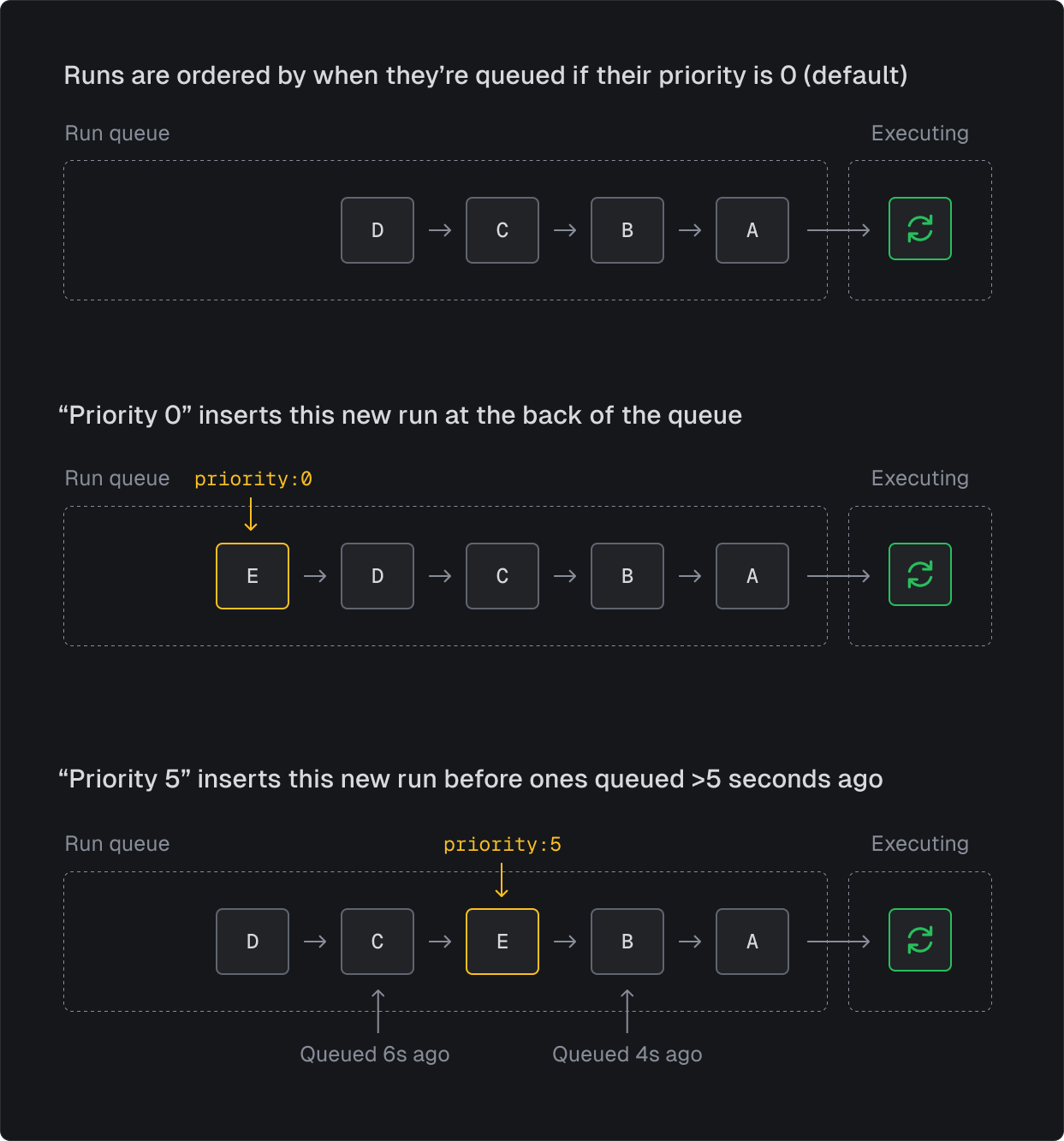
If you specify a priority of 10 the run will dequeue before runs that were triggered with no priority 8 seconds ago, like in this example:
// no priority = 0await myTask.trigger({ foo: "bar" });//... imagine 8s pass by// this run will start before the run above that was triggered 8s ago (with no priority)await myTask.trigger({ foo: "bar" }, { priority: 10 });
If you passed a value of 3600 the run would dequeue before runs that were triggered an hour ago (with no priority).
NOTE
Setting a high priority will not allow you to beat runs from other organizations. It will only affect the order of your own runs.
Queues and pausing
You can now pause an environment to stop runs from being started (and of course resume it again). This is really useful if you accidentally ship a bug and need an emergency stop.
If you're using the v4 packages, you can view a table of all your queues along with their stats. You can also pause and resume individual queues.
We've added some queue functions to the SDK. You can retrieve a queue including its stats:
// You can retrieve a queue by id, they start with queue_const queue = await queues.retrieve(ctx.queue.id);// Or use the type and name// The default queue for your "my-task-id"const q2 = await queues.retrieve({ type: "task", name: "my-task-id" });// The custom queue you defined in your codeconst q3 = await queues.retrieve({ type: "custom", name: "my-custom-queue" });
You can also pause and resume a queue:
// Pause using the id or the type and nameawait queues.pause(ctx.queue.id);// Resume using the id or the type and nameawait queues.resume({ type: "task", name: "my-task-id" });
If you're already using custom queues, you will need to make some minor code updates:
- You can't set
concurrencyLimitwhen you trigger a task anymore. You must define custom queues in your trigger folder before running the dev/deploy CLI commands. - You can continue to use
concurrencyKeywhen triggering, to allow per-user concurrency. - When a
waitis hit, the concurrency will be held by the queue by default. This means it will respect theconcurrencyLimitif you defined one. You can setreleaseConcurrencyOnWaitpoint: trueto release the concurrency to override this. You can also set this on your custom queue or when you use the wait functions.
Read the full details in our migration guide.
Middleware and lifecycle hooks
We have improved our middleware, lifecycle hooks, and added locals.
The new middleware system wraps around the other lifecycle hooks and your run function. Combined with locals it makes some problems easy to solve.
In this example, we have a single file that handles our Prisma database connection. That includes disconnecting if we do a wait inside our run. This is important if you do long waits because you should return database connections to the pool.
import { locals, tasks } from "@trigger.dev/sdk";import { PrismaClient } from "@prisma/client";// Use the type of your database client, PrismaClient in this caseconst DbLocal = locals.create<PrismaClient>("db");// A convenience function to get the database clientexport function getDb() { return locals.getOrThrow(DbLocal);}// Middleware is run around every run// You need to give them a unique name (e.g. `db`)tasks.middleware("db", async ({ ctx, payload, next, task }) => { // Create your database client before a run starts const db = locals.set(DbLocal, new PrismaClient()); // With Prisma you don't need to explicitly connect // It will happen lazily when the first query is made await db.$connect(); // Other middleware will run // After all of them, the run and lifecycle hooks will execute await next(); // This happens after the run and all lifecycle hooks are finished await db.$disconnect();});// This lifecycle hook is called when a `wait` is hit// In cloud this can result in the machine being suspended until latertasks.onWait("db", async ({ ctx, payload, task }) => { const db = getDb(); await db.$disconnect(); // This frees a database connection});// This lifecycle hook is called when a run is resumed after a `wait`tasks.onResume("db", async ({ ctx, payload, task }) => { const db = getDb(); // Technically with Prisma you don't need to explicitly connect again // It will happen lazily when the first query is made await db.$connect();});
Then in your task code you would use the getDb() function to get the database client.
import { getDb } from "./db";export const myTask = task({ run: async (payload) => { // This will be typed correctly const db = getDb(); await db.user.findFirst({ where: { id: payload.userId } }); },});
As shown above, you can now declare your lifecycle hooks in any file. Previously, this was only possible in the trigger.config file.
If you create a init.ts file at the root of your trigger directory, it will be automatically loaded when a task is executed. This is useful if you want to register global lifecycle hooks, or initialize a database connection, etc. Otherwise you just need to make sure your file is imported by a task somewhere to ensure it's bundled.
We have added some new lifecycle hooks:
onWaitis fired when anywaitis called. On cloud the machine may suspend (to be resumed later).onResumeis fired when a run is resumed after await.onCompleteis fired when a run completes, success or failure.
An MCP server built into our CLI
What self-respecting dev tool doesn't have an MCP server these days?
When you run the trigger dev command you can pass --mcp to start a local MCP server. This works well with Cursor, Claude Code, etc. to make triggering and debugging runs easier.
It can trigger tasks, get task runs, get run logs, cancel runs and get possible tasks. With these tools it can help you debug your code.
Other improvements
We have made a lot of other smaller improvements, like:
- You don't need to
exporttasks or queues anymore, we detect them anyway. This kept tripping people up. - We prioritize finishing runs vs starting new runs.
- Dequeuing runs is faster and fairer.
Our internal systems are much faster with higher throughput. This is mainly because we moved our internal queues from Postgres to Redis.
Self-hosting
We're working on a guide on how to self-host v4, which unlike v3, supports multiple worker servers. We will also publish an official Kubernetes guide for the first time, with a Helm chart.
Self-hosted workers
Unfortunately, the self-hosted workers we promised in our Run Engine 2.0 post hit some major snags during development.
We want them to be easy to set up and use, but they also need to support atomic versioning. Atomic versions mean you don't need to worry that deploying a new version will break any executing runs. Each deploy is a new separate version and all versions can run at the same time.
This is really important when you're running a production system. A deploy shouldn't turn off a worker server in the middle of run execution. You also shouldn't need to think about the version of the code changing mid execution.
For atomic versions to work you need to keep every deploy around and be able to run multiple versions at once. This requires something like Kubernetes, Docker with nested containers, or bare metal with MicroVMs. This is what we do in the cloud, but it's a lot of complexity to manage. We're going to have to think about how to make this simple for self-hosted workers.
If you're happy using the cloud product but need access to private services, we are going to be working on:
- Static IPs you can whitelist.
- VPC peering.
Vote on those and subscribe to notifications so you get an email when they're released.
Other worker regions
Our current workers are in us-east. When v4 is Generally Available (GA) we will add more worker regions based on demand. Please vote on the regions below:
Request other regions, or any other features, here.
How to use v4
Version 4 is in beta on the Trigger.dev cloud from today. We'll be rolling out regular fixes and updates over the next month before it becomes GA.
Read the upgrade guide for how to try it.
There are only a few minor breaking changes. Most projects won't have to make any changes apart from upgrading the packages.









