

Today the developer preview is live. Each day we'll let in more people as we fix bugs, increase capacity and roll out essential features. Create a free account to join the waitlist and we'll let you know when you get access.
We built v3 based on conversations with hundreds of users over the past year.
This video shows off writing tasks in a /trigger folder, running locally using our CLI and using the dashboard to view a run.
And here's the code for the task shown in that video:
No timeouts but still serverless
Timeouts are a big problem for background tasks, especially when even seemingly short tasks can hit the limits when you factor in retrying.
We learned this the hard way with v2 because code ran on your servers (often with timeouts). This meant you needed to divide tasks into small chunks which is complex, makes many things impossible (no chunk can exceed the timeout), and can lead to subtle bugs.
There are zero timeouts in v3. We deploy, manage and scale your tasks on long-running servers.
Writing tasks is now far simpler, less confusing and entirely new use cases are opened up.
Freeze your server costs
With our cloud product, you only pay when code is executing. This doesn't seem particularly novel until you realize that there are no timeouts and you can write code like this:
export const sendReminderEmail = task({ id: "send-reminder-email", run: async (payload: { todoId: string; userId: string; date: string }) => { //wait until the date, this could be a really long time in the future await wait.until({ date: new Date(payload.date) }); const todo = await prisma.todo.findUnique({ where: { id: payload.todoId, }, }); const user = await prisma.user.findUnique({ where: { id: payload.userId, }, }); //send email const { data, error } = await resend.emails.send({ from: "[email protected]", to: user.email, subject: `Don't forget to ${todo.title}!`, html: `<p>Hello ${user.name},</p><p>...</p>`, }); if (error) { throw new Error(`Failed to send email ${error.message} ${error.name}`); } logger.info(`Email sent to ${user.email}`, { data }); },});
If we can freeze the execution of your code we will, and you won't pay until it starts back up. Right now this happens when using the wait functions, after scheduling a retry, and when waiting for subtasks to complete.
The underlying technology we're using is called CRIU (Checkpoint/Restore In Userspace) and has been used at scale by Google since 2017. Each run has its own process that survives even after unfreezing. This is called Stateful Serverless and can simplify solving many problems.
Reliable by default
If a task throws an error (that you don't catch) it will be reattempted by default. Here you can see it happening 3 times:
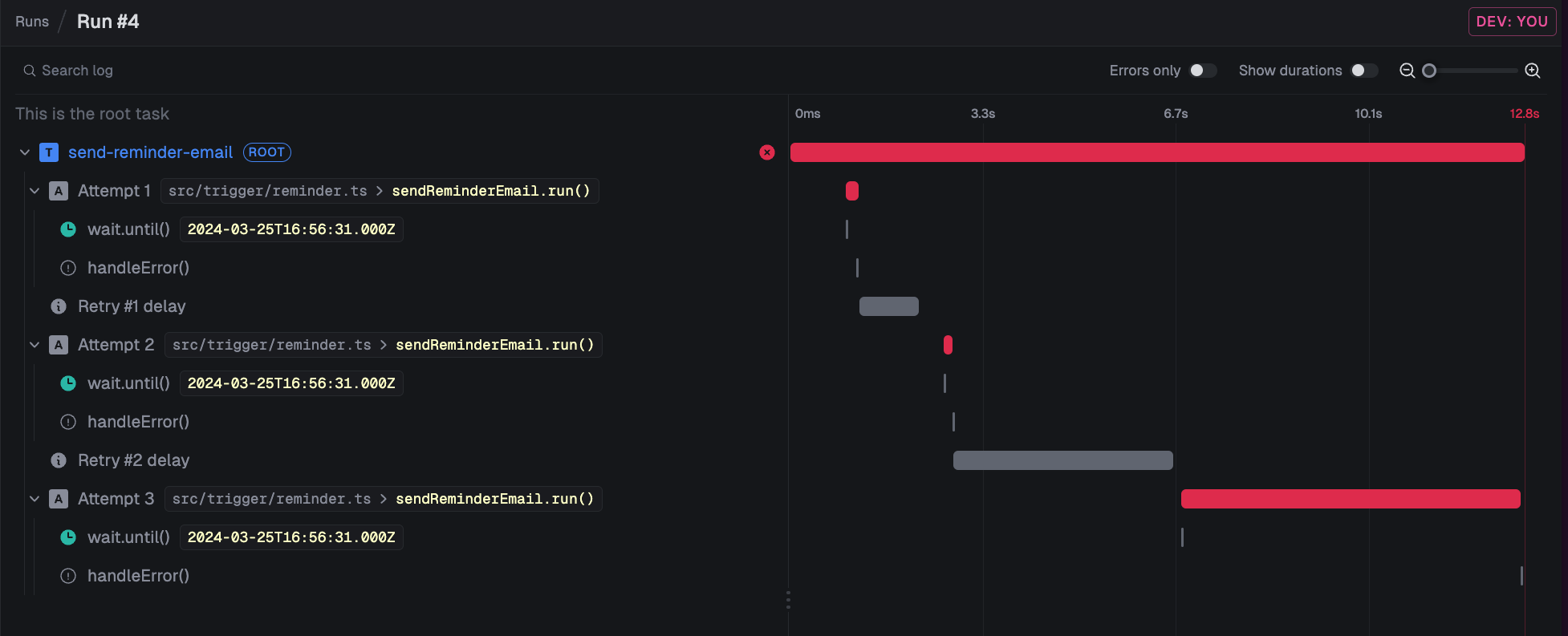
You can combine and nest tasks to create robust workflows easily:
export const myTask = task({ id: "my-task", retry: { maxAttempts: 10, }, run: async (payload: string) => { const result = await otherTask.triggerAndWait({ payload: "some data" }); //...do other stuff },});export const otherTask = task({ id: "other-task", retry: { maxAttempts: 5, }, run: async (payload: string) => { return { foo: "bar", }; },});
You can configure the default retrying behavior in your trigger.config.ts file.
We also provide some convenient functions that allow you to easily add reliability inside of your tasks, like retry.fetch() and retry.onThrow(). They use the freezing system when waiting to retry. Or you can use npm packages to do this if you'd prefer.
Observability built for long-running tasks
You get a live view into exactly what's happening in your tasks. We did this by extending OpenTelemetry (OTEL).
We automatically generate useful spans and logs when you trigger and run tasks. Plus anytime you log something in your code it will appear.
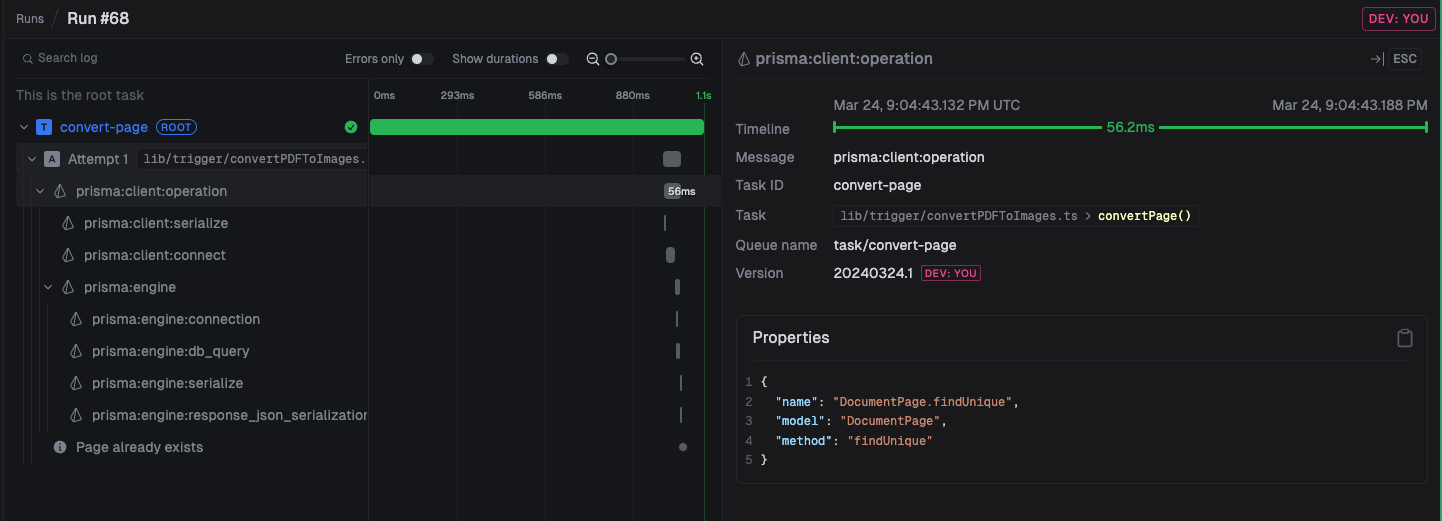
Here you can see Prisma calls being auto-instrumented. You don't need to do anything to get this level of observability. You can specify them in the trigger.config.ts file:
Open source
Our GitHub repo is Apache 2 licensed and we really appreciate issues, discussions, and contributions. You can self-host Trigger.dev v3 on your own infrastructure using Docker. We will be adding self-hosting guides soon.
Cloud pricing
Right now, v3 is invite-only and is free for a short period. Create a free account to join the v3 waitlist and we'll let you know when you have access.
You can view our pricing plans and usage pricing on the pricing page.
What's available and what's coming soon
Available
- Regular tasks
- Cron tasks
- Testing tasks from dashboard
- Triggering a run/batch of runs
- Trigger and wait for result for a run/batch of runs
- Concurrency controls
- Per-tenant queues
- Deploy via CLI
- Deploy via GitHub Actions
- Automatic reattempts
- Atomic versioning
- Useful local retrying functions
Coming soon
- Self-hosting guide for our Docker provider
- Zod tasks
- Full text search of all runs
- All logs view with full text search
- Alerts for errors
- Notifications: send data to your web app from inside a run
- Rollbacks: easily rollback changes when errors happen
- Webhook integrations (receiving a Stripe webhook triggers a task)
Let us know what we should prioritize and what we are missing.









