
Building production-grade AI agents requires more than just calling OpenAI's API. You need long-running tasks, durability, queues, and, crucially, the ability to show your users what's happening in real-time. That last piece turned out to be harder than we thought.
When we set out to build Trigger.dev's Realtime service, we knew we wanted something that could handle serious scale. We ended up with a system that processes over 20,000 run updates per second and ingests over 500GB of data daily from Postgres. But getting there required some unexpected technical decisions.
Here's how we built it, what worked, what didn't, and why we ended up using Postgres replication over WebSockets.
Note: Realtime also supports streaming data in real-time from inside your tasks, but this post focuses on how we built the core Realtime infrastructure.
The problem: Making background jobs feel foreground
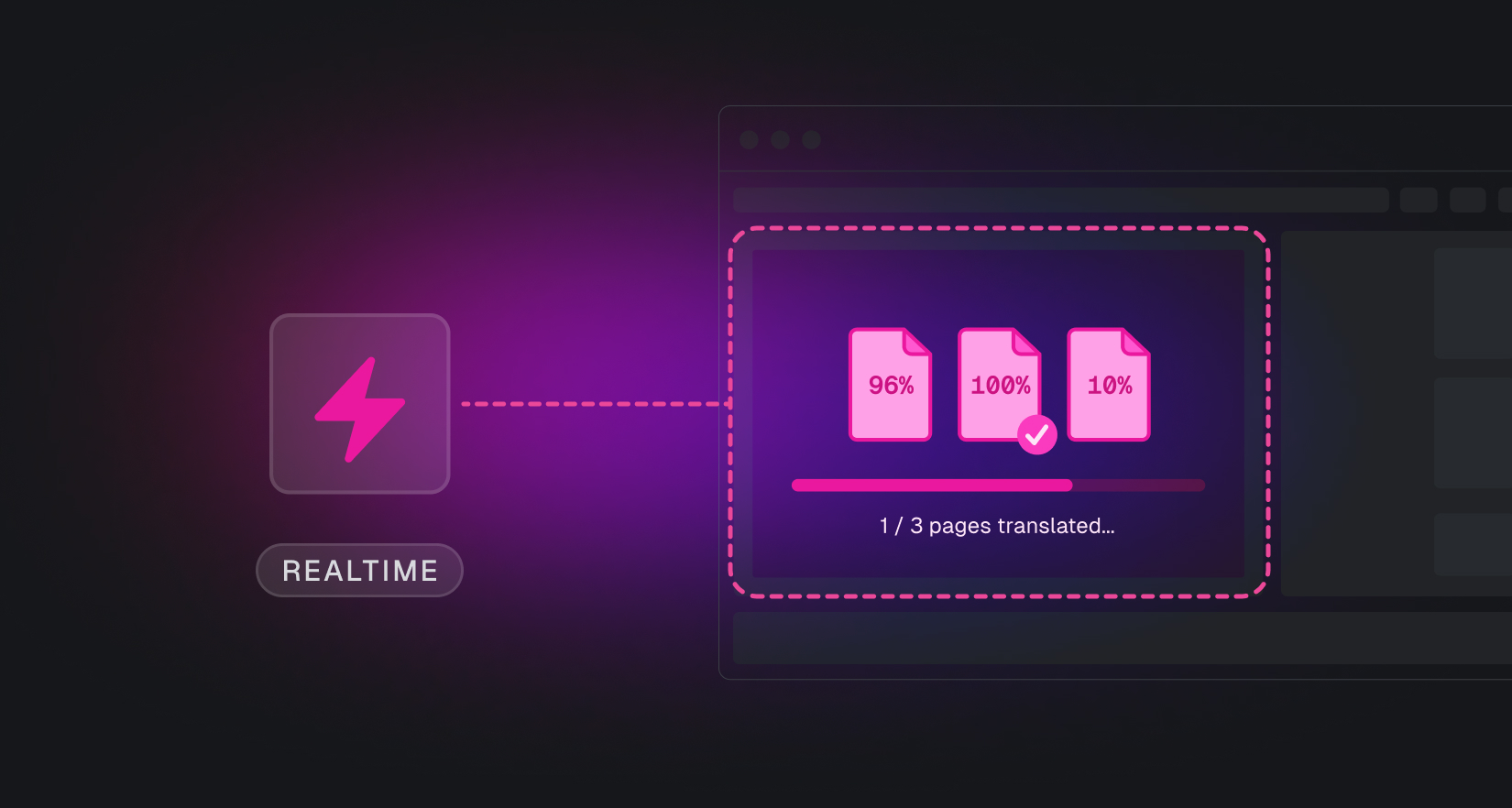
Trigger.dev helps developers build reliable background tasks, from AI agents and video generation to data pipelines and automation workflows. But "background" doesn't mean "invisible." Users want to see progress bars, get real-time updates, and know their jobs are actually working.
Consider this simple CSV processor:
You upload a 10,000-row file, and our system spawns tasks to process each row in parallel across many machines. Without real-time updates, users stare at a loading spinner for minutes, wondering if anything is happening. With Realtime, they see progress bars updating as each row gets processed, metadata flowing in, and confidence that their job is working.
Here's how to write the task that processes each row:
/** * This task is triggered for every CSV row */export const handleCSVRow = task({ id: "handle-csv-row", run: async (row: CSVRow) => { logger.info("Handling CSV row", { row }); const result = await processRow(row); // Update the parent metadata metadata.parent.increment("totalProcessed", 1); // Update this task's metadata metadata.set("result", result); return { result }; },});
On the frontend, developers can subscribe to these changes using our React hook:
export function CSVProgress({ runId, accessToken,}: { runId: string; accessToken: string;}) { const { run } = useRealtimeRun<typeof csvProcessor>(runId, { accessToken, }); const processed = run?.metadata.get("totalProcessed") ?? 0; const total = run?.metadata.get("total") ?? 1; return <span>{Math.round((processed / total) * 100)}%</span>;}
Architecture: Why we chose Postgres replication slots
Our first instinct was WebSockets. Everyone uses WebSockets for real-time, right? But we quickly hit on three key problems:
- Historical subscriptions: We want you to be able to subscribe to runs that started before you opened the page.
- Database load: Every WebSocket connection needs to query the database for initial state, then maintain a separate connection for updates.
- Notification complexity: WebSockets need a separate system to know when data changes. You have to use database triggers, message queues, or polling mechanisms to notify connected clients about updates. This is challenging in a high throughput system.
Then we discovered Electric which uses Postgres replication slots. This solved these problems, kept one source of truth, and reduced database load.
Here's how it works:

Updating a run
- When a task calls
metadata.set("foo", "bar"), it updates the runs table in Postgres - Postgres writes this change to its Write-Ahead Log (WAL)
Subscribing to a run
- An end-user loads a web page which uses Trigger.dev Realtime.
- An HTTP request is sent to Trigger.dev to authenticate them (using JWT).
- If authenticated we create a query for Electric to process.
- ElectricSQL creates a new “Shape” (if no query param was passed) and does an initial query for the run to Postgres.
- The returned row includes a transaction ID (which is sent back and used as a cursor from now on).
From now on, the client sends the shape and transaction IDs in all requests. When they're present, ElectricSQL knows it's in "live mode" and sends new changes only for that shape.
The HTTP request is a long poll which returns a new row when there's a change or 20s have passed. When the Response is received the client will do another request (unless the run is completed).
How Postgres replication slots actually work
Let's dig into how replication slots work:
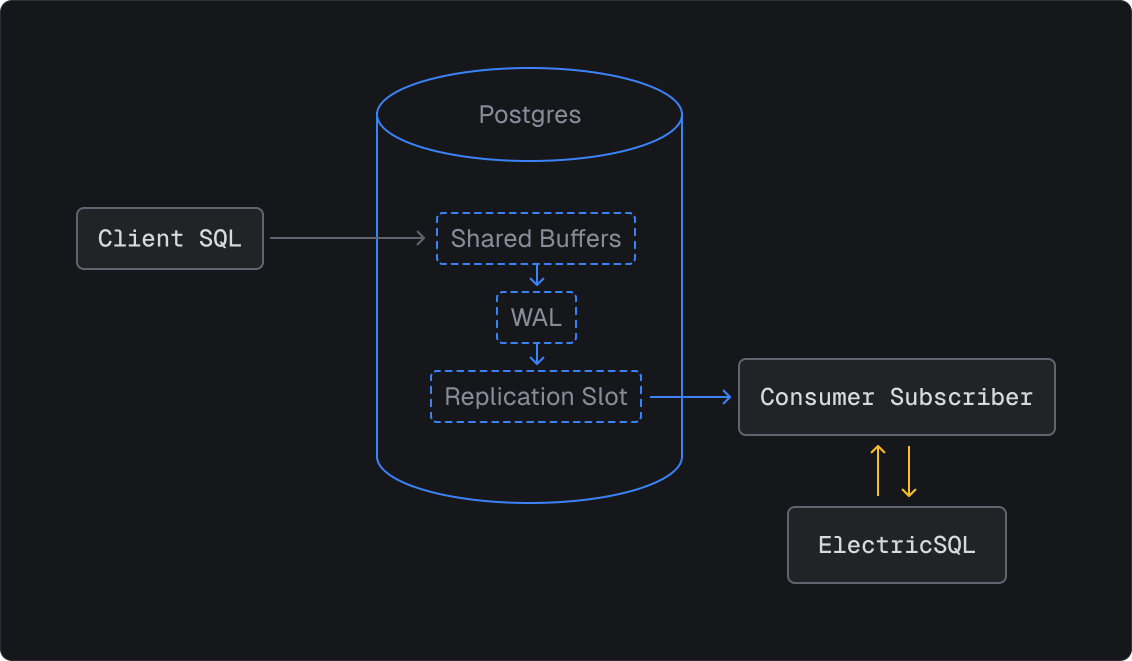
- A SQL query is made to the database (that modifies data).
- Postgres parses the SQL, plans, then executes the query.
- Data changes are cached in shared buffers.
- Changes are appended to the Write-Ahead Log (WAL).
- The replication slot acts as a persistent bookmark, tracking the latest WAL position processed for that slot.
- ElectricSQL connects and streams changes, moving the cursor forward.
- We get a reliable, ordered stream of every database change.
Combining an initial query, then subsequent long-polling requests using the replication stream we get a reliable live view of the data.
Authentication: JWTs all the way down
For auth, we use signed JSON Web Tokens instead of hitting the database on every request. This was crucial for performance.
const publicToken = await auth.createPublicToken({ scopes: { read: { runs: ["run_1234", "run_5678"], // ✅ this token can read only these runs }, },});
The JWT is signed with our API key and includes permission scopes—whether the user can trigger tasks, read specific runs, or subscribe to runs with certain tags.
The beauty of this is that no database query is required to verify permissions. If the JWT is valid, we know they have permission.
Rate limiting: Redis Lua scripts
We limit our Realtime connections based on subscription plans. 500 concurrent connections by default on the Pro plan, for example.
We use a sliding window algorithm implemented as a Redis Lua script to achieve this.
local concurrencyKey = KEYS[1]local timestamp = tonumber(ARGV[1])local requestId = ARGV[2]local expiryTime = tonumber(ARGV[3])local cutoffTime = tonumber(ARGV[4])local limit = tonumber(ARGV[5])-- Remove expired entriesredis.call('ZREMRANGEBYSCORE', concurrencyKey, '-inf', cutoffTime)-- Add the new request to the sorted setredis.call('ZADD', concurrencyKey, timestamp, requestId)-- Set the expiry time on the keyredis.call('EXPIRE', concurrencyKey, expiryTime)-- Get the total number of concurrent requestslocal totalRequests = redis.call('ZCARD', concurrencyKey)-- Check if the limit has been exceededif totalRequests > limit then -- Remove the request we just added redis.call('ZREM', concurrencyKey, requestId) return 0end-- Return 1 to indicate successreturn 1
Each request expires after 5 minutes. We count active connections in a sliding window and reject new ones if they'd exceed the limit. Lua scripts run atomically in Redis, so we don't have race conditions.
Time filtering and caching challenges
One tricky problem: developers want to subscribe to "all runs created in the last hour" or "all runs with tag 'org_1234' from today." But ElectricSQL Shapes need fixed WHERE clauses. If the createdAt filter changes on every React render, we'd create infinite shapes and destroy performance.
Our solution: cache the time filters against the shape ID.
const cache = createCache({ createdAtFilter: new Namespace<string>(ctx, { stores: [memory, redisCacheStore], fresh: 60_000 * 60 * 24 * 7, // 1 week stale: 60_000 * 60 * 24 * 14, // 2 weeks }),});const createdAtFilterCacheResult = await this.cache.createdAtFilter.get( shapeId);
We're using the excellent @unkey/cache package, which gives us memory + Redis caching with automatic freshness guarantees. This lets us have many servers running the same caching logic without stepping on each other.
Performance: The numbers that matter
After months of optimization, here's what we achieved:
- 20,000 updates per second during peak loads
- 500GB+ of Postgres inserts processed daily
- Sub-100ms latency for real-time updates to reach browsers
The Postgres + ElectricSQL architecture scales surprisingly well. Postgres handles the write load because that's what it's designed for. ElectricSQL handles the fan-out to browsers.
Why ElectricSQL over alternatives
We evaluated several approaches but ElectricSQL solved our core problem: we already needed the data in Postgres for persistence. Why not use Postgres as the source of truth for real-time updates too?
The WAL-based approach means:
- Users can subscribe to any run after the fact
- We get strong consistency guarantees
- Operational complexity stays low
- We minimize load on our primary database
Want to try Trigger.dev Realtime? Check out our Realtime docs and run through our React hooks guide.









