
Anthropic published a thoughtful blog post about building AI agents, where they make a compelling case for keeping things simple: use straightforward, composable patterns instead of getting tangled up in complex frameworks. Their key insight? Focus on specific tasks rather than trying to build do-it-all agents.
I wanted to take these ideas and show how they work in practice. This article walks through each workflow with real examples using Trigger.dev, Vercel's AI SDK, and OpenAI.
Prompt chaining
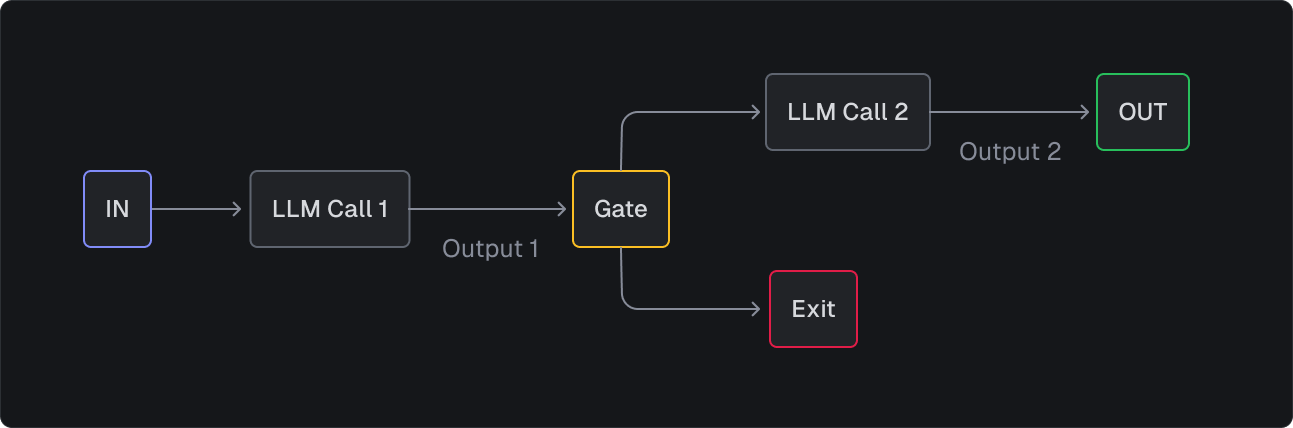
Let's start with prompt chaining, which is probably the simplest pattern in the toolkit. Think of it as breaking down a complex task into a series of smaller, more manageable steps. Instead of asking an LLM to do everything at once, you guide it through a predetermined sequence.
The beauty of prompt chaining is that it's predictable and easy to debug since you know exactly what's happening at each step. Plus, by breaking things down, you often get better results than trying to tackle everything in one giant prompt.
Example: Prompt chaining
- Generate marketing copy on a subject you provide. (LLM call 1)
- Check the word count fits a target range. (Gate)
- Take the output and translate it into a target language. (LLM call 2)
Notice that we're using the experimental_telemetry option from the Vercel AI SDK to enable telemetry for the task. This is useful for debugging and getting more details on each LLM call.
import { openai } from "@ai-sdk/openai";import { task } from "@trigger.dev/sdk";import { generateText } from "ai";export interface TranslatePayload { marketingSubject: string; targetLanguage: string; targetWordCount: number;}export const generateAndTranslateTask = task({ id: "generate-and-translate-copy", maxDuration: 300, // Stop executing after 5 mins of compute run: async (payload: TranslatePayload) => { // Step 1: Generate marketing copy const generatedCopy = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "You are an expert copywriter.", }, { role: "user", content: `Generate as close as possible to ${payload.targetWordCount} words of compelling marketing copy for ${payload.marketingSubject}`, }, ], experimental_telemetry: { isEnabled: true, functionId: "generate-and-translate-copy", }, }); // Gate: Validate the generated copy meets the word count target const wordCount = generatedCopy.text.split(/\s+/).length; if ( wordCount < payload.targetWordCount - 10 || wordCount > payload.targetWordCount + 10 ) { throw new Error( `Generated copy length (${wordCount} words) is outside acceptable range of ${ payload.targetWordCount - 10 }-${payload.targetWordCount + 10} words` ); } // Step 2: Translate to target language const translatedCopy = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: `You are an expert translator specializing in marketing content translation into ${payload.targetLanguage}.`, }, { role: "user", content: `Translate the following marketing copy to ${payload.targetLanguage}, maintaining the same tone and marketing impact:\n\n${generatedCopy}`, }, ], experimental_telemetry: { isEnabled: true, functionId: "generate-and-translate-copy", }, }); return { englishCopy: generatedCopy, translatedCopy, }; },});
If we trigger this task with the following payload, it generates this run for us in the Trigger.dev dashboard:
{ marketingSubject: "The controversial new Jaguar electric concept car", targetLanguage: "Spanish", targetWordCount: 100,}
Routing
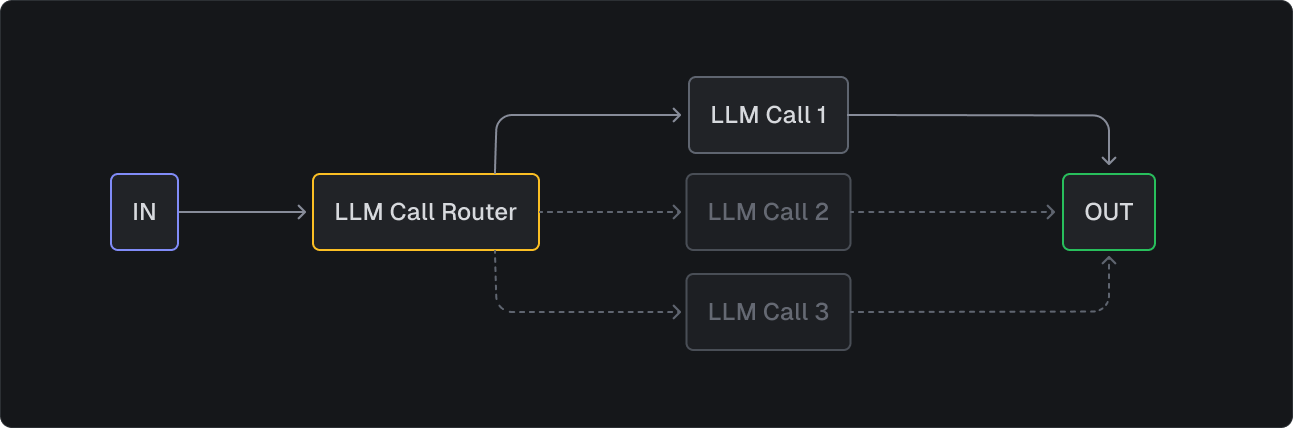
You can think of routing as an AI traffic controller. Instead of forcing one LLM to handle everything, you first figure out what type of task you're dealing with, then send it to the right specialist.
Example: Routing
- User asks a question.
- Determine if the question is simple or complex.
- Use the appropriate model to answer the question.
- Return the answer, model used, and reasoning.
You'll notice there's a lot of prompts in these examples. As you develop your prompts, you'll likely want to iterate and refine them over time. I recommend using tools like Langfuse or Langsmith for prompt management and metrics, making it easier to track performance and make improvements.
import { openai } from "@ai-sdk/openai";import { task } from "@trigger.dev/sdk";import { generateText } from "ai";import { z } from "zod";// Schema for router responseconst routingSchema = z.object({ model: z.enum(["gpt-4o", "gpt-o3-mini"]), reason: z.string(),});// Router prompt templateconst ROUTER_PROMPT = `You are a routing assistant that determines the complexity of questions.Analyze the following question and route it to the appropriate model:- Use "gpt-4o" for simple, common, or straightforward questions- Use "gpt-o3-mini" for complex, unusual, or questions requiring deep reasoningRespond with a JSON object in this exact format:{"model": "gpt-4o" or "gpt-o3-mini", "reason": "your reasoning here"}Question: `;export const routeAndAnswerQuestion = task({ id: "route-and-answer-question", run: async (payload: { question: string }) => { // Step 1: Route the question const routingResponse = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "You must respond with a valid JSON object containing only 'model' and 'reason' fields. No markdown, no backticks, no explanation.", }, { role: "user", content: ROUTER_PROMPT + payload.question, }, ], temperature: 0.1, experimental_telemetry: { isEnabled: true, functionId: "route-and-answer-question", }, }); // Add error handling and cleanup let jsonText = routingResponse.text.trim(); if (jsonText.startsWith("```")) { jsonText = jsonText.replace(/```json\n|\n```/g, ""); } const routingResult = routingSchema.parse(JSON.parse(jsonText)); // Step 2: Get the answer using the selected model const answerResult = await generateText({ model: openai(routingResult.model), messages: [{ role: "user", content: payload.question }], }); return { answer: answerResult.text, selectedModel: routingResult.model, routingReason: routingResult.reason, }; },});
Triggering our task with a simple question shows it routing to the gpt-4o model and returning the answer with reasoning:
{ question: "How many planets are there in the solar system?"}
Parallelization

Sometimes you need to do multiple things at once – that's where parallelization comes in. Rather than working through tasks one by one, you split them up and run them simultaneously. This is where batch.triggerByTaskAndWait shines, allowing you to execute multiple tasks in parallel and efficiently coordinate their responses.
Example: Parallelization
This example responds to customer questions by simultaneously generating a response and checking for inappropriate content.
3 tasks handle this:
- The first generates a response to the user's question.
- The second task checks for innapropriate content.
- The third, main task coordinates the responses by using
batch.triggerByTaskAndWaitto run the two tasks in parallel. If the content is inappropriate, this task returns a message saying it can't process the request, otherwise it returns the generated response.
import { openai } from "@ai-sdk/openai";import { batch, task } from "@trigger.dev/sdk";import { generateText } from "ai";// Task to generate customer responseexport const generateCustomerResponse = task({ id: "generate-customer-response", run: async (payload: { question: string }) => { const response = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "You are a helpful customer service representative.", }, { role: "user", content: payload.question }, ], experimental_telemetry: { isEnabled: true, functionId: "generate-customer-response", }, }); return response.text; },});// Task to check for inappropriate contentexport const checkInappropriateContent = task({ id: "check-inappropriate-content", run: async (payload: { text: string }) => { const response = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "You are a content moderator. Respond with 'true' if the content is inappropriate or contains harmful, threatening, offensive, or explicit content, 'false' otherwise.", }, { role: "user", content: payload.text }, ], experimental_telemetry: { isEnabled: true, functionId: "check-inappropriate-content", }, }); return response.text.toLowerCase().includes("true"); },});// Main task that coordinates the parallel executionexport const handleCustomerQuestion = task({ id: "handle-customer-question", run: async (payload: { question: string }) => { const { runs: [responseRun, moderationRun], } = await batch.triggerByTaskAndWait([ { task: generateCustomerResponse, payload: { question: payload.question }, }, { task: checkInappropriateContent, payload: { text: payload.question }, }, ]); // Check moderation result first if (moderationRun.ok && moderationRun.output === true) { return { response: "I apologize, but I cannot process this request as it contains inappropriate content.", wasInappropriate: true, }; } // Return the generated response if everything is ok if (responseRun.ok) { return { response: responseRun.output, wasInappropriate: false, }; } // Handle any errors throw new Error("Failed to process customer question"); },});
When we trigger our task with a question, you can see the 2 LLM calls running in parallel using batch.triggerByTaskAndWait. The main task waits for both to complete before returning a response.
{ "question": "Can you explain 2FA?"}
Orchestrator-workers
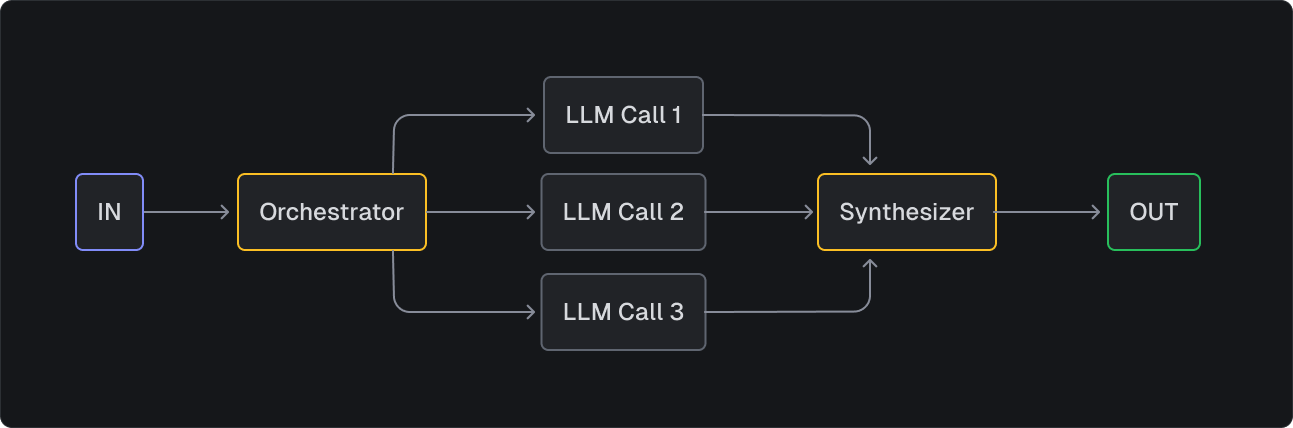
This pattern is like having a project manager (the orchestrator) who breaks down a big job into smaller tasks and assigns them to specialists (the workers). The orchestrator keeps track of everything and puts all the pieces back together at the end. Using batch.triggerByTaskAndWait, it efficiently coordinates multiple tasks while maintaining clear control over the entire workflow.
Example: Orchestrator-workers
- Extracts distinct factual claims from a news article.
- Verifies each claim by considering recent news sources and official statements.
- Analyzes the historical context of each claim in the context of past announcements and technological feasibility.
- Returns the claims, verifications, and historical analyses.
import { openai } from "@ai-sdk/openai";import { batch, logger, task } from "@trigger.dev/sdk";import { CoreMessage, generateText } from "ai";// Define types for our workers' outputsinterface Claim { id: number; text: string;}interface SourceVerification { claimId: number; isVerified: boolean; confidence: number; explanation: string;}interface HistoricalAnalysis { claimId: number; feasibility: number; historicalContext: string;}// Worker 1: Claim Extractorexport const extractClaims = task({ id: "extract-claims", run: async ({ article }: { article: string }) => { try { const messages: CoreMessage[] = [ { role: "system", content: "Extract distinct factual claims from the news article. Format as numbered claims.", }, { role: "user", content: article, }, ]; const response = await generateText({ model: openai("o1-mini"), messages, }); const claims = response.text .split("\n") .filter((line: string) => line.trim()) .map((claim: string, index: number) => ({ id: index + 1, text: claim.replace(/^\d+\.\s*/, ""), })); logger.info("Extracted claims", { claimCount: claims.length }); return claims; } catch (error) { logger.error("Error in claim extraction", { error: error instanceof Error ? error.message : "Unknown error", }); throw error; } },});// Worker 2: Source Verifierexport const verifySource = task({ id: "verify-source", run: async (claim: Claim) => { const response = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "Verify this claim by considering recent news sources and official statements. Assess reliability.", }, { role: "user", content: claim.text, }, ], experimental_telemetry: { isEnabled: true, functionId: "verify-source", }, }); return { claimId: claim.id, isVerified: false, confidence: 0.7, explanation: response.text, }; },});// Worker 3: Historical Context Analyzerexport const analyzeHistory = task({ id: "analyze-history", run: async (claim: Claim) => { const response = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: "Analyze this claim in historical context, considering past announcements and technological feasibility.", }, { role: "user", content: claim.text, }, ], experimental_telemetry: { isEnabled: true, functionId: "analyze-history", }, }); return { claimId: claim.id, feasibility: 0.8, historicalContext: response.text, }; },});// Orchestratorexport const newsFactChecker = task({ id: "news-fact-checker", run: async ({ article }: { article: string }) => { // Step 1: Extract claims const claimsResult = await batch.triggerByTaskAndWait([ { task: extractClaims, payload: { article } }, ]); if (!claimsResult.runs[0].ok) { logger.error("Failed to extract claims", { error: claimsResult.runs[0].error, runId: claimsResult.runs[0].id, }); throw new Error( `Failed to extract claims: ${claimsResult.runs[0].error}` ); } const claims = claimsResult.runs[0].output; // Step 2: Process claims in parallel const parallelResults = await batch.triggerByTaskAndWait([ ...claims.map((claim) => ({ task: verifySource, payload: claim })), ...claims.map((claim) => ({ task: analyzeHistory, payload: claim })), ]); // Split and process results const verifications = parallelResults.runs .filter( (run): run is typeof run & { ok: true } => run.ok && run.taskIdentifier === "verify-source" ) .map((run) => run.output as SourceVerification); const historicalAnalyses = parallelResults.runs .filter( (run): run is typeof run & { ok: true } => run.ok && run.taskIdentifier === "analyze-history" ) .map((run) => run.output as HistoricalAnalysis); return { claims, verifications, historicalAnalyses }; },});
When we trigger our task with the article payload below, we make 3 separate LLM calls. One for extracting claims, one for verifying each claim, and one for analyzing the historical context of each claim. The orchestrator task waits for all 3 to complete before returning a response using batch.triggerByTaskAndWait.
{ "article": "Tesla announced a new breakthrough in battery technology today. The company claims their new batteries will have 50% more capacity and cost 30% less to produce. Elon Musk stated this development will enable electric vehicles to achieve price parity with gasoline cars by 2024. The new batteries are scheduled to enter production next quarter at the Texas Gigafactory."}
Evaluator-optimizer
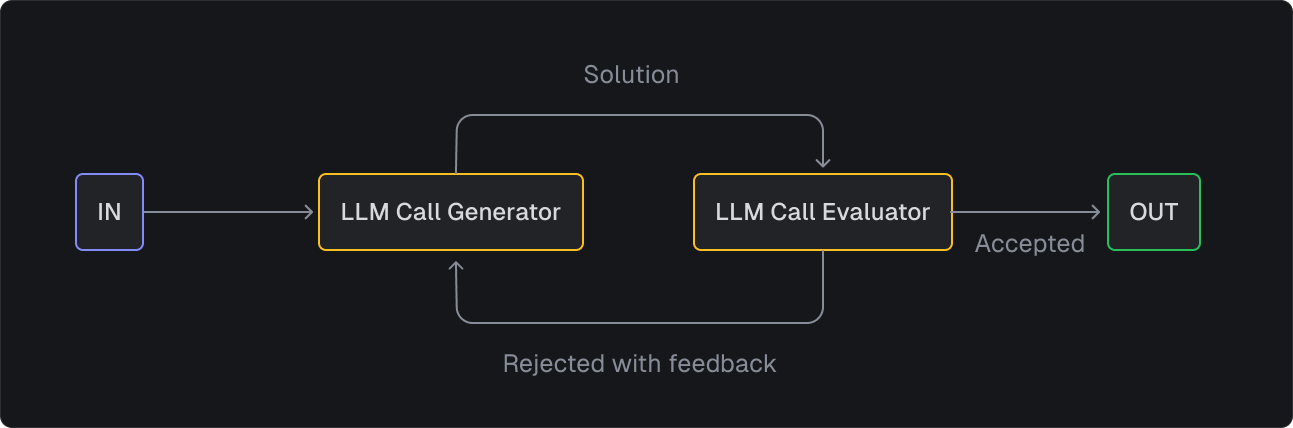
Here's where you add quality control to your AI system. The evaluator checks the output, and if it's not quite right, the optimizer suggests improvements. Think of it as having a friendly editor who reviews your work and helps make it better.
Example: Evaluator-optimizer
- Generates a translation of the text.
- Evaluates the translation.
- If the translation is good, returns the final result.
- If the translation is not good, recursively calls the task with the translation and feedback.
import { task } from "@trigger.dev/sdk";import { generateText } from "ai";import { openai } from "@ai-sdk/openai";interface TranslationPayload { text: string; targetLanguage: string; previousTranslation?: string; feedback?: string; rejectionCount?: number;}export const translateAndRefine = task({ id: "translate-and-refine", run: async (payload: TranslationPayload) => { const rejectionCount = payload.rejectionCount || 0; // Bail out if we've hit the maximum attempts if (rejectionCount >= 10) { return { finalTranslation: payload.previousTranslation, iterations: rejectionCount, status: "MAX_ITERATIONS_REACHED", }; } // Generate translation (or refinement if we have previous feedback) const translationPrompt = payload.feedback ? `Previous translation: "${payload.previousTranslation}"\n\nFeedback received: "${payload.feedback}"\n\nPlease provide an improved translation addressing this feedback.` : `Translate this text into ${payload.targetLanguage}, preserving style and meaning: "${payload.text}"`; const translation = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: `You are an expert literary translator into ${payload.targetLanguage}. Focus on accuracy first, then style and natural flow.`, }, { role: "user", content: translationPrompt, }, ], experimental_telemetry: { isEnabled: true, functionId: "translate-and-refine", }, }); // Evaluate the translation const evaluation = await generateText({ model: openai("o1-mini"), messages: [ { role: "system", content: `You are an expert literary critic and translator focused on practical, high-quality translations. Your goal is to ensure translations are accurate and natural, but not necessarily perfect. This is iteration ${ rejectionCount + 1 } of a maximum 5 iterations. RESPONSE FORMAT: - If the translation meets 90%+ quality: Respond with exactly "APPROVED" (nothing else) - If improvements are needed: Provide only the specific issues that must be fixed Evaluation criteria: - Accuracy of meaning (primary importance) - Natural flow in the target language - Preservation of key style elements DO NOT provide detailed analysis, suggestions, or compliments. DO NOT include the translation in your response. IMPORTANT RULES: - First iteration MUST receive feedback for improvement - Be very strict on accuracy in early iterations - After 3 iterations, lower quality threshold to 85%`, }, { role: "user", content: `Original: "${payload.text}" Translation: "${translation.text}" Target Language: ${payload.targetLanguage} Iteration: ${rejectionCount + 1} Previous Feedback: ${ payload.feedback ? `"${payload.feedback}"` : "None" } ${ rejectionCount === 0 ? "This is the first attempt. Find aspects to improve." : 'Either respond with exactly "APPROVED" or provide only critical issues that must be fixed.' }`, }, ], experimental_telemetry: { isEnabled: true, functionId: "translate-and-refine", }, }); // If approved, return the final result if (evaluation.text.trim() === "APPROVED") { return { finalTranslation: translation.text, iterations: rejectionCount, status: "APPROVED", }; } // If not approved, recursively call the task with feedback await translateAndRefine .triggerAndWait({ text: payload.text, targetLanguage: payload.targetLanguage, previousTranslation: translation.text, feedback: evaluation.text, rejectionCount: rejectionCount + 1, }) .unwrap(); },});
When we run this example you can see how our payload text below is translated into French and then refined over a max of 10 iterations. The evaluator is satisfied with the result after the 2nd iteration in this case and returns the final translation.
{ "text": "In the twilight of his years, the old clockmaker's hands, once steady as the timepieces he crafted, now trembled like autumn leaves in the wind.", "targetLanguage": "French"}
Conclusion
Building effective AI agents doesn't have to be complicated – as Anthropic points out, simpler patterns often work better than complex frameworks. Whether you're chaining prompts together, routing tasks to specialized models, or orchestrating multiple workers, the key is to keep your approach focused and modular.
Give these patterns a try in your Trigger.dev project today. Start simple, see what works for your use case, and build from there.
Next steps
- Create a Trigger.dev account
- Check out our Quick Start guide
- View the examples in our GitHub repo
- Join our Discord community to share your implementations and get help
- Read the Anthropic article
- Try implementing the simplest Prompt chaining pattern in your project










