
Starting in 3.3.14, you can automatically retry runs that fail from a suspected Out Of Memory (OOM) crash.
Out Of Memory crashes happen when one of your runs is trying to access more memory than is available and Garbage Collection (GC) didn't free up enough memory to continue. This can happen when you're processing large files, images, video, or other data that requires a lot of memory.
Before we talk about the new retry feature, we need to talk about machines in general.
Machines
We support specifying the machine in a few different ways. Larger machines have more memory (and vCPUs).
Specifying the machine for a task:
import { task } from "@trigger.dev/sdk";export const heavyTask = task({ id: "heavy-task", // This is how you specify the machine for a task machine: "large-1x", run: async (payload) => { //...do heavy stuff },});
You can also override the task machine when you trigger it:
await heavyTask.triggerAndWait({ message: "hello world" }, { machine: "large-2x" });
This is useful when you know that a certain payload will require more memory than the default machine. For example, you know it's a larger file or a customer that has a lot of data.
Retry OOM errors
If you are seeing a lot of OOM errors then you need to either optimize your code to use less memory or increase the machine size, as described above.
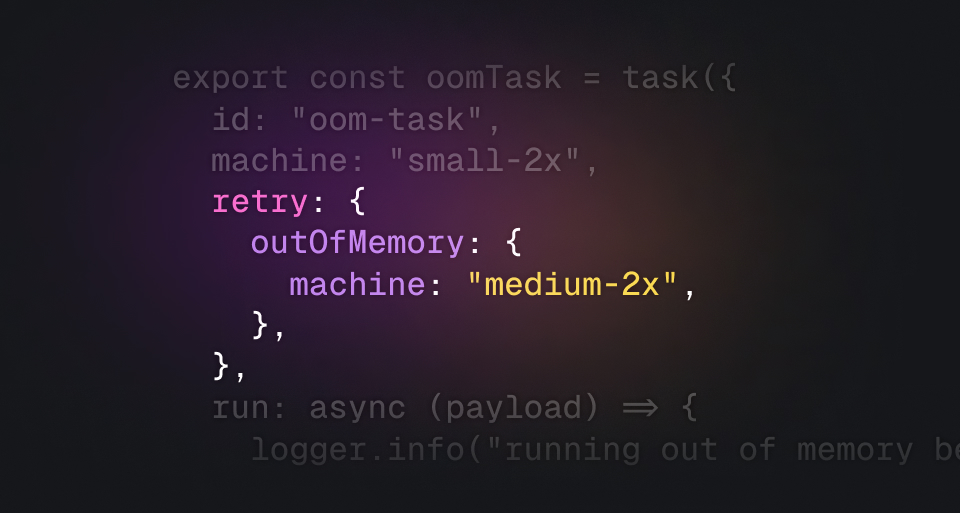
However, there are situations where you want to automatically retry an OOM failure on a larger machine. This is where the new retry feature comes in:
import { task } from "@trigger.dev/sdk";export const heavyTask = task({ id: "heavy-task", // It will use this machine by default machine: "medium-1x", retry: { // If the task fails with an OOM error, it will retry on this machine outOfMemory: { machine: "large-1x", }, }, run: async (payload) => { //...do heavy stuff },});
If an attempt fails with an OOM error, the run will automatically retry on the machine you specify. If the larger machine fails again with an OOM error, it won't retry again because it won't succeed.
Runs will always start with the default machine, and only retry on the specified machine if they fail with an OOM error.
IMPORTANT
This is great when you have a small percentage of OOM errors for a task and you want to automatically retry them on a larger machine. But bear in mind that this isn't efficient because you have to get an OOM error first for this to kick in. That means you've wasted some compute time on the smaller machine.
Upgrading to 3.3.14+
Update to 3.3.14 or higher to use this new retry feature. Read our how to upgrade guide.